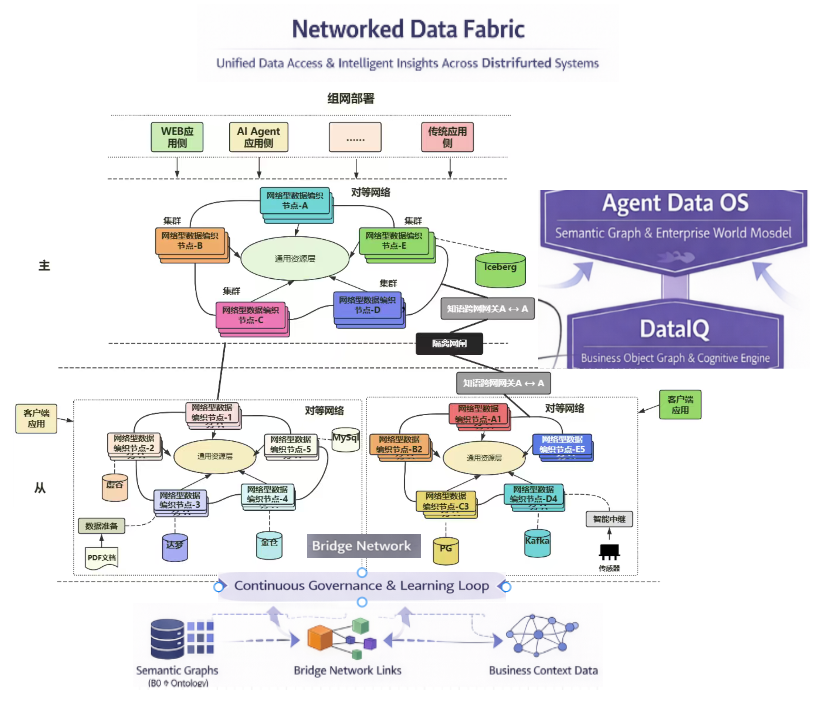
知语数据编织系统是知语数据智织架构体系中的数据智能层核心组件,致力于构建全域数据底座,核心目标通过“发现→编织→治理→服务化”的全链路流程让数据“可用”,打破数据孤岛,实现分布式多源异构数据的逻辑统一与高效流转。
破数据孤岛,实现分布式多源异构数据的逻辑统一与高效流转。
.png)
.png)
.png)
.png)
按数据结构类型分类,全面覆盖企业数据生态
| 数据源类型 | 新增 | 删除 | 修改 | 查询 |
|---|---|---|---|---|
| 结构化数据(关系型数据库 / 数仓) | ||||
| 知语 | ✔ | ✔ | ✔ | ✔ |
| PolarDB | - | - | - | ✔ |
| OceanBase | — | — | — | ✔ |
| 达梦 | ✔ | ✔ | ✔ | ✔ |
| 人大金仓 | — | — | — | ✔ |
| GaussDB | ✔ | ✔ | ✔ | ✔ |
| OpenGauss | ✔ | ✔ | ✔ | ✔ |
| 涛思 | - | - | - | ✔ |
| 虚谷 | - | - | - | ✔ |
| GoldenDB | - | - | - | ✔ |
| TiDB | - | - | - | ✔ |
| TDSQL | - | - | - | ✔ |
| YashanDB | - | - | - | ✔ |
| AnalyticDB | - | - | - | ✔ |
| KaiwuDB | - | - | - | ✔ |
| DolphinDB | - | - | - | ✔ |
| SelectDB | - | - | - | ✔ |
| 磐维数据库 | - | - | - | ✔ |
| Apache IoTDB | - | - | - | ✔ |
| Hologres | - | - | - | ✔ |
| MatrixOne | - | - | - | ✔ |
| Easysearch | - | - | - | ✔ |
| He3DB | - | - | - | ✔ |
| Milvus | - | - | - | ✔ |
| gStore | - | - | - | ✔ |
| CloudWave | - | - | - | ✔ |
| RisingWave | - | - | - | ✔ |
| 海量数据库 | ✔ | ✔ | ✔ | ✔ |
| StarRocks | — | — | — | ✔ |
| 瀚高 | — | — | — | ✔ |
| GBase | — | — | — | ✔ |
| MySQL | ✔ | ✔ | ✔ | ✔ |
| PostgreSQL | ✔ | ✔ | ✔ | ✔ |
| MariaDB | ✔ | ✔ | ✔ | ✔ |
| Oracle | — | — | — | ✔ |
| MSSQL | — | — | — | ✔ |
| 半结构化数据(NoSQL / JSON / 搜索引擎) | ||||
| MongoDB | ✔ | — | — | ✔ |
| Elasticsearch | — | — | — | ✔ |
| Redis | — | — | — | ✔ |
| Cassandra | — | — | — | ✔ |
| OpenAPI | — | — | — | ✔ |
| 表格文档 | — | — | — | ✔ |
| 非结构化 & 大数据(数据湖 / 流式 / OLAP) | ||||
| Hive | — | — | — | ✔ |
| Iceberg | ✔ | ✔ | ✔ | ✔ |
| Delta Lake | — | — | — | ✔ |
| Trino | — | — | — | ✔ |
| ClickHouse | — | — | — | ✔ |
| Apache Doris | ✔ | ✔ | ✔ | ✔ |
| Kafka | — | — | — | ✔ |
| Kafka-Connect | — | — | — | ✔ |
| MQTT | — | — | — | ✔ |
注:以上数据源支持情况基于 V2.7 版本,后续版本将持续扩展更多数据源类型与能力支持。
1. 虚拟化联邦:监控界面增加信息解释;
2. 编织门户:新增系统健康状态,各子系统实例状态监管;
3. 智能问数:新增提示词管理;
4. 虚拟化联邦:增加守护进行,防止client长时间占有连接,超时中断连接;
5. 修订已知问题;
6. 优化部分功能。